파이썬 셀레니움을 이용해 자동으로 크롬 창을 열어 특정 HTML 요소에 접근해보는 포스팅을 따라해봄
글의 목차
1. 파이썬 셀레니움을 이용하는 간단한 테스트를 위한 준비물
2. 파이썬과 셀레니움을 이용한 자동화 테스트를 진행하는 방법
1) HTML DOM 객체 접근
2) 윈도우와 프레임 접근
3) 테스트하기 이상적인 시간
4) 셀레니움과 파이썬 유닛 테스트 연동
3. 파이썬 셀레니움의 한계
1) 정리
※ 기초 예제 1에서는 목차 1,2만 다루고 2-1부터 3-1까지는 기초 예제 2에서 다룰 예정
1. 파이썬 셀레니움을 이용하는 간단한 테스트를 위한 준비물
pip install seleniumcmd 창에서 위의 명령어를 입력하여 selenium을 설치해준다
+셀레니움을 사용하기 위해서는 추가적으로 드라이버 설치가 필요하다
아래 링크에서 본인이 사용할 블라우저의 드라이버를 선택해서 설치하자
Chrome, Edge, Firefox, and Safari.
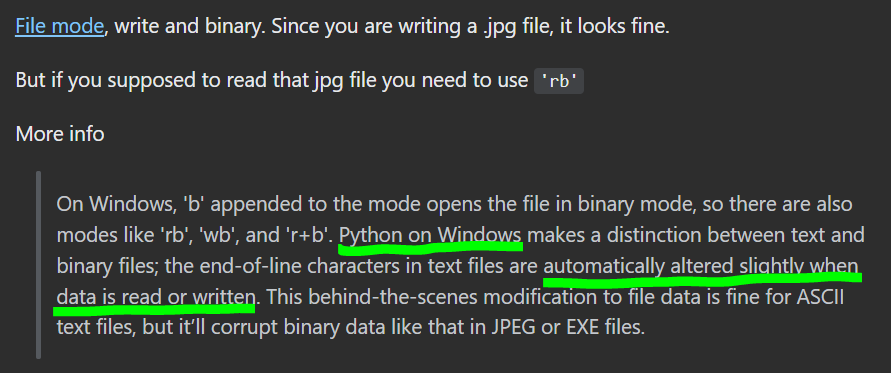
(만약 드라이버 실행 후 아래와 같은 문구가 나온다면 다른 버전의 크롬 드라이버가 필요한 것이니 당황하지 말고
본인이 사용하는 크롬 버전을 확인 후, 그에 맞는 버전의 드라이버를 추가해서 exe 파일을 교체해주면 된다)
selenium.common.exceptions.SessionNotCreatedException: Message: session not created: This version of ChromeDriver only supports Chrome version 94
Current browser version is 96.0.4664.93 with binary path C:\Program Files (x86)\Google\Chrome\Application\chrome.exe
로컬에서 셀레니움을 테스트한다면, 위의 과정만 진행해도 괜찮다
하지만 원격에서 셀레니움을 테스트하려고 한다면, 셀레니움 서버를 추가적으로 설치해줘야 한다
셀레니움 서버는 자바로 쓰여졌으므로 JRE1.6 또는 그 이상의 버전이 서버에 설치되어있어야 한다
다운로드는 아래 링크를 방문 ㄱㄱ
Selenium’s download page.
2. 파이썬과 셀레니움을 이용한 자동화 테스트를 진행하는 방법 (1-6)
1의 단계를 마쳤으면 파이썬 셀레니움 테스트를 진행할 준비가 끝났으니 아래의 단계를 진행해보자
1. Web driver와 Key 클래스 추가
from selenium import webdriver
from selenium.webdriver.common.keys import Keyswebdriver 클래스는 브라우저에 접근이 가능하도록 해주고
Keys 클래스는 Shift 등을 포함한 키보드 입력을 도와준다
2. 이전에 설치한 브라우저 웹 드라이버 (크롬 드라이버)의 경로 생성
driver = webdriver.Chrome('./chromedriver')로컬 환경에서 테스트한다면, 이 명령어는 로컬에서 크롬을 실행시키는 것과 같아서
close() 메소드를 사용할때까지 닫히지않는다
3. get() 메소드를 사용하여 웹사이트를 로드
driver.get("https://www.python.org")
4. 입력한 페이지 로드가 완료됐다면 .title 속성을 사용하여 웹페이지 제목 텍스트를 출력해볼수있다
print(driver.title)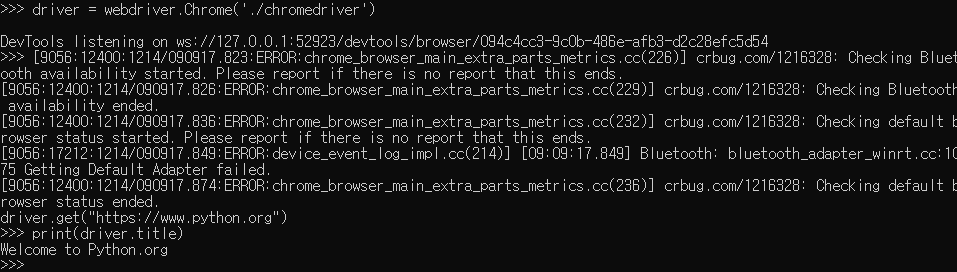
파이썬 인터프리터에서 직접 실행해보면 이렇게 출력이됨
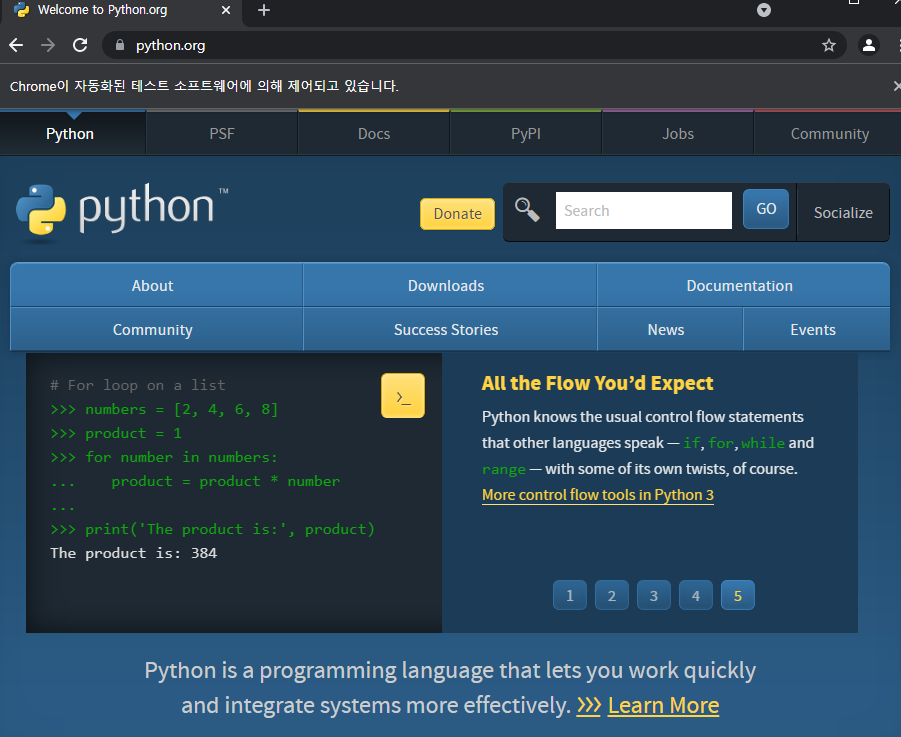
셀레니움으로 브라우저 창을 띄우면 자동화된 테스트 소프트웨어에 의해 제어되고 있다는 문구도 확인이 가능하다
5. 검색창에 접근해보자
f12를 눌러 HTML 엘레먼트 리스트에서 검색어 입력을 받는 DOM을 찾아 특정 값을 입력해준다
CSS 클래스, ID, name 등의 속성을 이용하여 DOM 접근이 가능하다
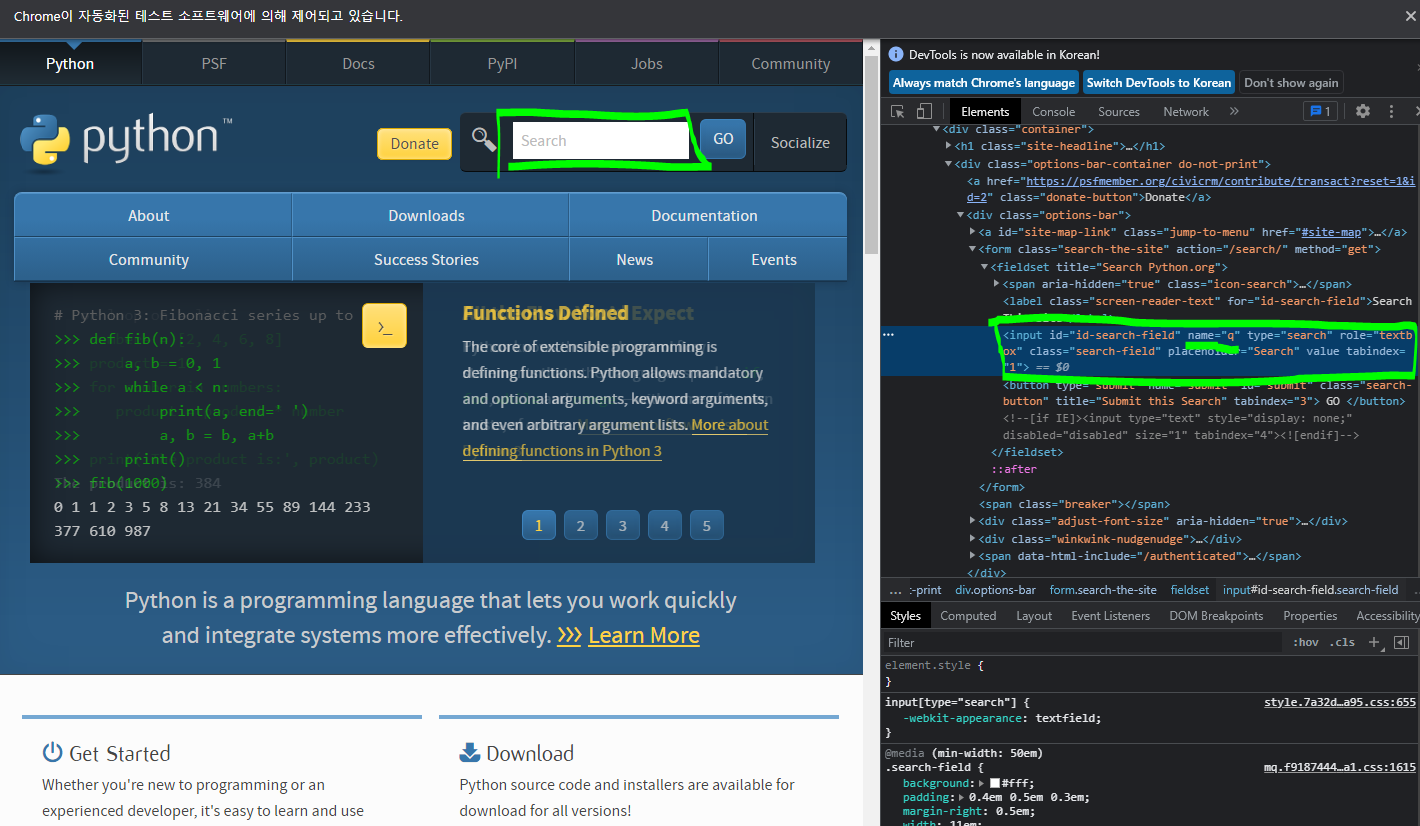
find_element_by_name() 메소드를 이용하면 된다
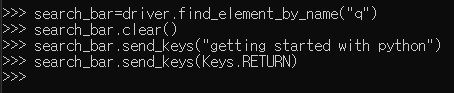
search_bar = driver.find_element_by_name("q")
파이썬 인터프리터에서 직접 실행하는 경우, 위와같은 워닝창이 뜨는데
한번 더 입력했더니 그냥 수용해줘서 그냥 썼음
6. DOM 엘레먼트 선택을 하고 clear() 메소드를 사용하여 기존에 있던 검색 창의 값을 초기화 시켜준다
그러고 전달하고 싶은 값을 send_keys() 메소드를 사용하여 입력해준다
search_bar.clear()
search_bar.send_keys("getting started with python")
search_bar.send_keys(Keys.RETURN)
#search_bar.send_keys(Keys.ENTER) - 이 방식도 위와 동일하게 작용Keys.RETURN을 주어 엔터 입력과 동일하게 사용
위의 과정을 거치는 동안 셀레니움을 통해 열었던 크롬 창의 url 이 바뀌어 있는것을 알수있다
print(driver.current_url)
print를 통해 url을 출력해보면 아래와 같이 나온다
'https://www.python.org/search/?q=getting+started+with+python&submit='
close() 메소드를 이용하여 열었던 크롬 창을 닫을수있다
driver.close()
위의 코드를 취합해본 코드
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
driver = webdriver.Chrome('./chromedriver')
driver.get("https://www.python.org")
print(driver.title)
search_bar = driver.find_element_by_name("q")
search_bar.clear()
search_bar.send_keys("getting started with python")
search_bar.send_keys(Keys.RETURN)
print(driver.current_url)
driver.close()
셀레니움을 이용한 웹 크롤링의 기본을 다뤄보았다
참고 : https://www.browserstack.com/guide/python-selenium-to-run-web-automation-test
Selenium with Python : Getting Started with Automation | BrowserStack
Learn to use Selenium Python to run web automation tests with ease. Read this step-by-step tutorial on how to run your first test using Selenium & Python.
www.browserstack.com
https://stackoverflow.com/questions/1629053/typing-the-enter-return-key-in-selenium
Typing the Enter/Return key in Selenium
I'm looking for a quick way to type the Enter or Return key in Selenium. Unfortunately, the form I'm trying to test (not my own code, so I can't modify) doesn't have a Submit button. When working w...
stackoverflow.com
'파이썬' 카테고리의 다른 글
| [python] 파이썬 에러 TypeError: can only concatenate str (not "Tag") to str (0) | 2021.12.10 |
|---|---|
| [python] 파이썬 에러 TypeError: write() argument must be str (0) | 2021.11.27 |
| [python] 파이썬 윈도우 설치 방법과 환경변수 세팅 (0) | 2021.11.25 |
| [python] 윈도우 cmd 에서 파이썬 설치 버전과 경로 확인하는 법 (0) | 2021.01.27 |